Oracle Cloud Always Free では、実行中であってもリソース消費の少ないインスタンスは アイドル 状態とみなされ、停止の上、 インスタンス が 回収 されてしまうとのことで、そうなる前に 回収 直前の インスタンス を再起動させ、stress-ngを使って一定以上のリソース消費を維持するようにしてみました。
実行中のはずのインスタンスが没収の危機
Oracle Cloudから何度か届いたインスタンスに関するメールでは、それほどクリティカルに受け止めませんでしたが、
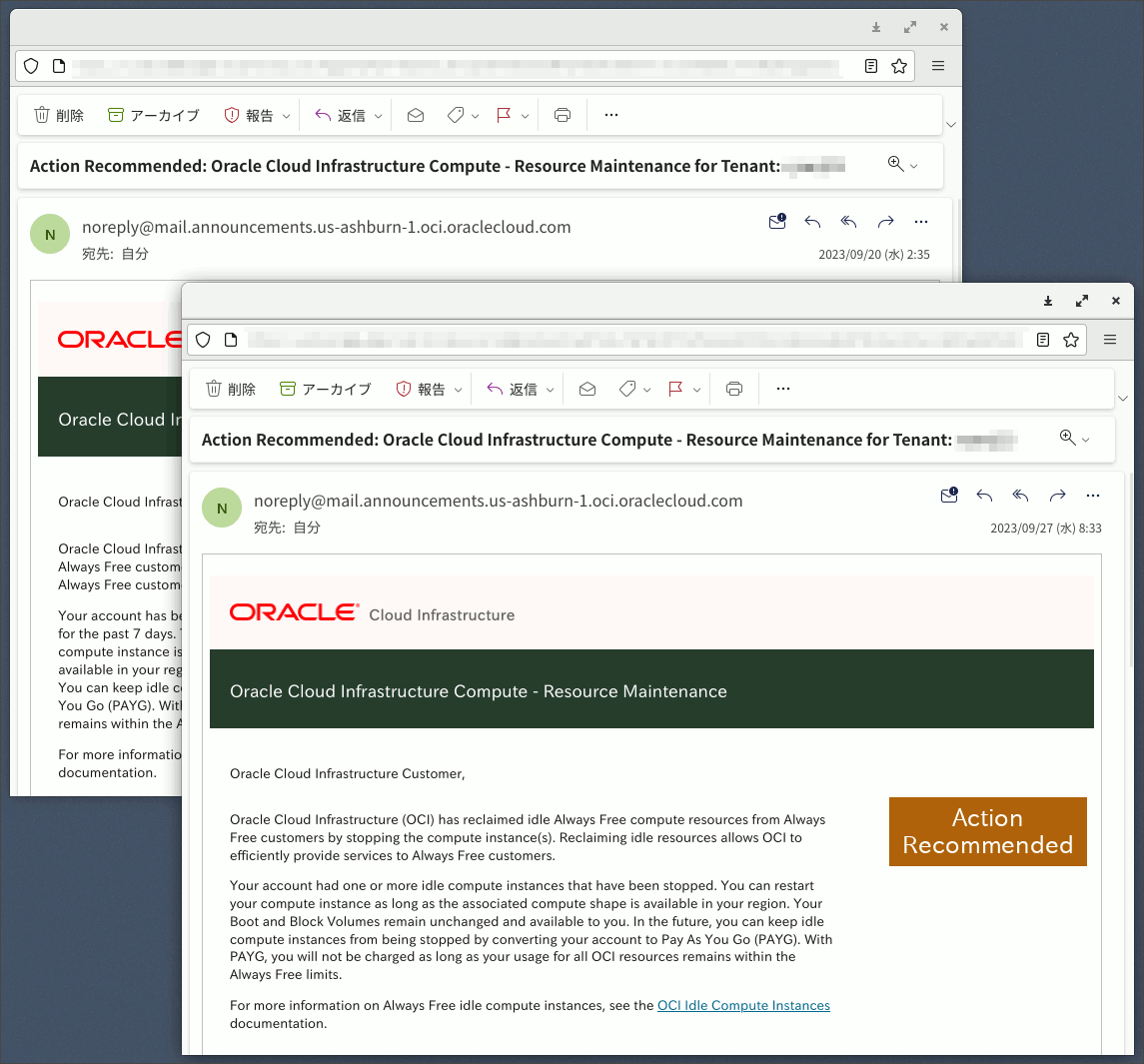
図1.OCIから届いたメール
Oracle Cloud Infrastructure Customer,
Oracle Cloud Infrastructure (OCI) has reclaimed idle Always Free compute resources from Always Free customers by stopping the compute instance(s). Reclaiming idle resources allows OCI to efficiently provide services to Always Free customers.
Your account had one or more idle compute instances that have been stopped. You can restart your compute instance as long as the associated compute shape is available in your region. Your Boot and Block Volumes remain unchanged and available to you. In the future, you can keep idle compute instances from being stopped by converting your account to Pay As You Go (PAYG). With PAYG, you will not be charged as long as your usage for all OCI resources remains within the Always Free limits.
For more information on Always Free idle compute instances, see the OCI Idle Compute Instances documentation.
念の為、ブラウザでインスタンスを確認してみると、以前、NextCloud環境を構築して上記稼働しているはずのインスタンスが停止していてびっくり。急ぎ起動しました。

図2.停止していたインスタンス起動
無事に起動後、中へ入ってシステムログを確認すると、日付がばっさり飛んでいる部分を発見。エージェント経由でのやんわりとしたシャットダウン処理ではなく、スイッチを切るような停止処理だったようです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
Sep 27 01:37:19 ubnxc systemd[1]: Started Firmware update daemon. Sep 27 01:37:19 ubnxc fwupdmgr[883245]: Updating lvfs Sep 27 01:37:19 ubnxc fwupdmgr[883245]: Downloading…: 0% Sep 27 01:37:19 ubnxc fwupdmgr[883245]: Downloading…: 100% Sep 27 01:37:19 ubnxc fwupdmgr[883245]: Idle…: 100% Sep 27 01:37:19 ubnxc fwupdmgr[883245]: Downloading…: 100% Sep 27 01:37:19 ubnxc fwupdmgr[883245]: Downloading…: 1% Sep 27 01:37:19 ubnxc fwupdmgr[883245]: Downloading…: 3% Sep 27 01:37:19 ubnxc fwupdmgr[883245]: Downloading…: 6% Sep 27 01:37:19 ubnxc fwupdmgr[883245]: Downloading…: 8% Sep 27 01:37:19 ubnxc fwupdmgr[883245]: Downloading…: 12% Sep 27 01:37:19 ubnxc fwupdmgr[883245]: Downloading…: 15% Sep 27 01:37:19 ubnxc fwupdmgr[883245]: Downloading…: 100% Sep 27 01:37:19 ubnxc fwupdmgr[883245]: Idle…: 100% Sep 27 01:37:20 ubnxc fwupdmgr[883245]: Successfully downloaded new metadata: 0 local devices supported Sep 27 01:37:20 ubnxc systemd[1]: fwupd-refresh.service: Succeeded. Sep 27 01:37:20 ubnxc systemd[1]: Finished Refresh fwupd metadata and update motd. Sep 27 09:21:11 ubnxc systemd-random-seed[502]: Kernel entropy pool is not initialized yet, waiting until it is. Sep 27 09:21:11 ubnxc systemd[1]: Finished Set the console keyboard layout. Sep 27 09:21:11 ubnxc systemd[1]: Mounted FUSE Control File System. Sep 27 09:21:11 ubnxc systemd[1]: Mounted Kernel Configuration File System. Sep 27 09:21:11 ubnxc systemd[1]: Starting Flush Journal to Persistent Storage... Sep 27 09:21:11 ubnxc systemd-sysctl[503]: Not setting net/ipv4/conf/all/promote_secondaries (explicit setting exists). Sep 27 09:21:11 ubnxc systemd-sysctl[503]: Not setting net/ipv4/conf/default/promote_secondaries (explicit setting exists). |
このインスタンスへ仕込んでいたNetdataでも(関連記事はこちら)、インスタンス停止によるデータ途絶が見て取れます。
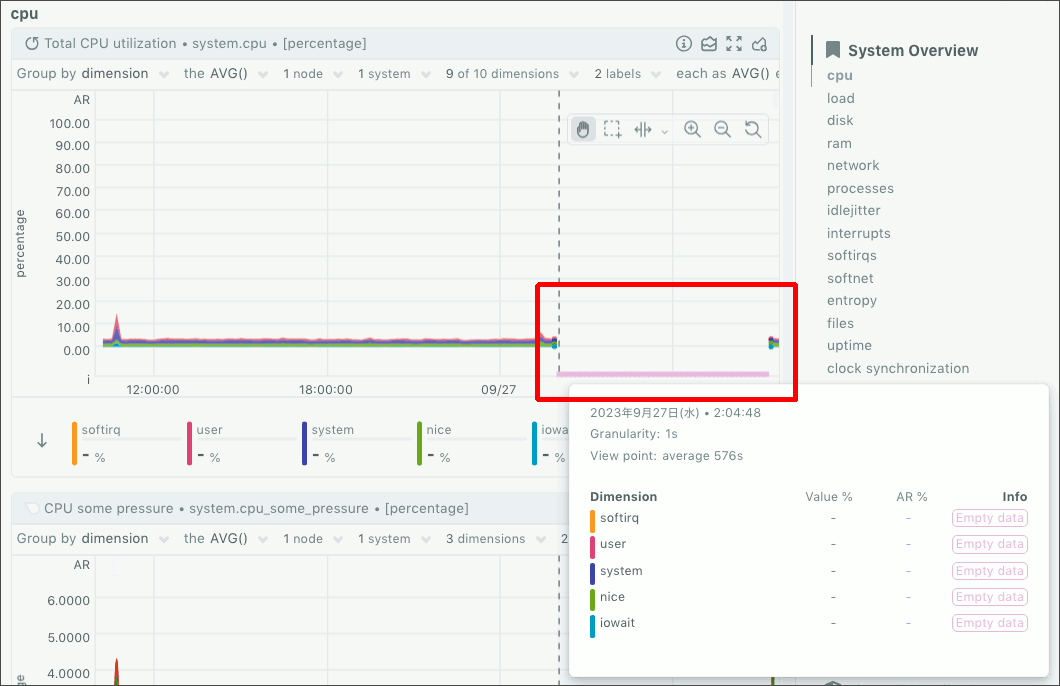
図3.停止していたことをNetdataで確認
アイドルインスタンスの回収とは
どういうことなのか調べてたどり着いたこちらの記事とYoutube動画に、いきさつから対策まで詳しく解説されていました(Great Works!)。


曰く、たとえ実行中のインスタンスであっても、リソース使用率があるしきい値を下回っていると「アイドル状態」とみなされ、インスタンス停止の上に回収されてしまうというもの。
問題のしきい値は、上述の記事の当時は15%程度だったようですが、本記事執筆時点では更に20%にまで上昇していました(2023年09月現在)。

図4.アイドルインスタンス回収定義
このままOCIの思惑通りにPAYGアカウントへ移行するのが無難とは思いますが、先ほどの記事を参考に多少悪あがきしてみたいと思います(以降はあくまで自己責任で)。
stress-ngでインスタンスを忙しく
その方策とは、主にシステムの負荷試験などで使われるstress-ngを使い、しきい値を超えるリソース消費をインスタンスに維持させるというものです。

インスタンスはUbuntu 22.04ベースなので、aptパッケージマネージャからインストール。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
$ apt list stress-ng -a stress-ng/focal-updates 0.11.07-1ubuntu2 arm64 stress-ng/focal 0.11.07-1 arm64 $ sudo apt install stress-ng The following additional packages will be installed: libjudydebian1 libsctp1 Suggested packages: lksctp-tools The following NEW packages will be installed: libjudydebian1 libsctp1 stress-ng 0 upgraded, 3 newly installed, 0 to remove and 68 not upgraded. Need to get 492 kB of archives. After this operation, 1,839 kB of additional disk space will be used. Do you want to continue? [Y/n] y $ whereis stress-ng stress-ng: /usr/bin/stress-ng /usr/share/stress-ng /usr/share/man/man1/stress-ng.1.gz $ stress-ng --version stress-ng, version 0.11.07 (gcc 9.4, aarch64 Linux 5.15.0-1042-oracle) 💻🔥 |
参考元の記事ではCPU、メモリへの負荷をそれぞれ別プロセスで動かしていましたが、1つのプロセスで済ませることも可能です。
|
1 2 3 4 5 |
$ stress-ng --cpu 1 --cpu-load 20 --vm 1 --vm-bytes 20% --vm-hang 0 stress-ng: info: [32141] defaulting to a 86400 second (1 day, 0.00 secs) run per stressor stress-ng: info: [32141] dispatching hogs: 1 cpu, 1 vm ^C stress-ng: info: [32141] successful run completed in 1590.11s (26 mins, 30.11 secs) |
期待通りに動作することを確認したら、これをsystemdへサービスとして登録します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[Unit] Description=Stress-NG Playing 20% Working After=network.target [Service] Type=simple ExecStart=/usr/bin/stress-ng --cpu 1 --cpu-load 20 --vm 1 --vm-bytes 20%% --vm-hang 0 User=root Group=root RestartSec=10 Restart=always [Install] WantedBy=multi-user.target |
※サービスファイル内において%はダメ文字なので、%%と重ねてエスケープ処理しています。
作成したサービスを有効化して起動します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
$ sudo systemctl enable stress-ng.service Created symlink /etc/systemd/system/multi-user.target.wants/stress-ng.service → /etc/systemd/system/stress-ng.service. $ sudo systemctl start stress-ng.service $ systemctl status stress-ng.service ● stress-ng.service - Stress-NG Playing 20% Working Loaded: loaded (/etc/systemd/system/stress-ng.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2023-09-27 15:06:52 HKT; 5s ago Main PID: 36988 (stress-ng) Tasks: 4 (limit: 6961) Memory: 681.7M CGroup: /system.slice/stress-ng.service ├─36988 /usr/bin/stress-ng --cpu 1 --cpu-load 20 --vm 1 --vm-bytes 20% --vm-hang 0 ├─36989 stress-ng-cpu . ├─36990 stress-ng-vm . └─36991 stress-ng-vm . |
Netdata上やOCIのインスタンスのメトリック上でも、CPUとメモリにしきい値を超える消費が確認されました。
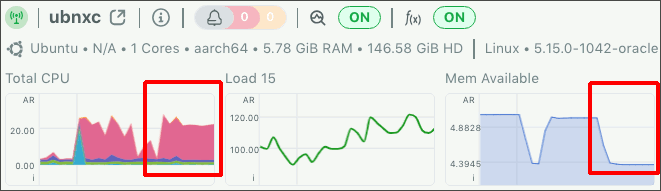
図5.stress-ng 20%をNetdataで確認
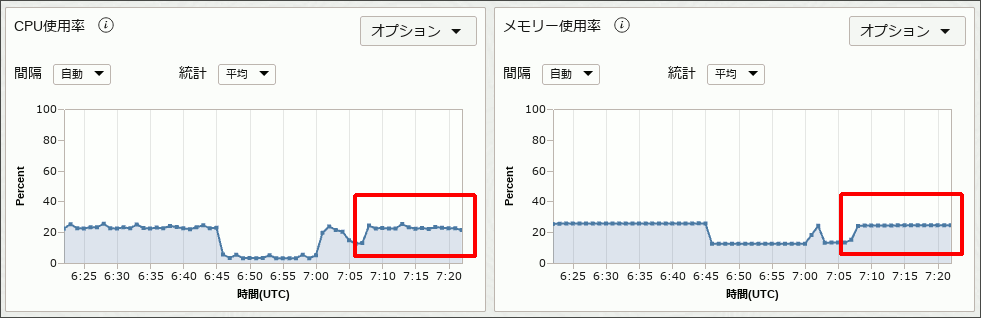
図6.stress-ng 20%をOCIメトリックで確認
stress-ngはオプションで指定しない限り、デフォルトでは24時間経過するとプロセスが終了するのですが、サービス化によりまた新たにプロセスが立ち上がるようにしてあります。
これでまた動きがあれば、また書き足すつもりです。
